Research Question
How did the COVID-19 pandemic reshape the likelihood that an interventional clinical trial registered on ClinicalTrials.gov would both begin and reach completion?
More precisely, I track how yearly attempts (new trial registrations), successes (completed trials with posted results), and failures (terminated or withdrawn trials) shifted across three windows: pre-pandemic (2015-2019), pandemic onset (2020-2021), and early-recovery (2022-2025). I layered in sponsor type, participant age, and other study-design details, and I aim to reveal which corners of the research pipeline proved resilient and which still show scarring.
Data & Key Variables
The analysis draws on the Aggregate Analysis of ClinicalTrials.gov (AACT) relational database, a public mirror of every record on ClinicalTrials.gov maintained by the Clinical Trials Transformation Initiative and refreshed daily. I worked with the static snapshot dated 1 April 2025 from the same date in 2015.
Core tables and fields include:
| Table → Field | What it represents | How I use it |
|---|---|---|
studies.first_posted_date | Date the trial was first registered | Counts attempts per year |
studies.overall_status | Current status (Completed, Terminated, Withdrawn, etc.) | Flags success vs. failure |
studies.results_first_posted_date | Date results were posted | Verifies that a “Completed” study reported outcomes |
sponsors.name | Lead sponsor (industry, academic, hospital, etc.) | Breaks out trends by top sponsors |
eligibilities.minimum_age / maximum_age | Age range of eligible participants | Groups trials into Child (<18) and Older Adult (≥65) cohorts |
Limitations & biases
Several limitations affect this analysis. Trials activated late in 2024 and 2025 are too recent to have reached completion, causing recent success rates to appear artificially low. Also, the registry does not always reflect reality because study teams may delay updating their trial statuses. Using a simple success-or-failure categorization also obscures important nuances, since intermediate statuses such as “Active, not recruiting” or “Suspended” are combined into these two categories. We must also consider that health-system disruptions varied significantly from country to country, yet each trial is treated equally, which masks important regional differences.
Interpreting the Numbers for a Non-Data Audience
Think of the global clinical-trial ecosystem as a production line. Attempts are raw materials entering the line, successes are finished products, and failures are discarded parts.
During 2020-21, the factory floor stayed open; raw material kept arriving. But staffing shortages, lockdowns, and hospital surges jammed the conveyor belts, so fewer products rolled off the line and more were scrapped.
The age-group view reveals where the choke points were sharpest. Pediatric studies rely on school clinics, parental consent, and specialized monitoring, something made all the more difficult due to the mid-pandemic. On the other hand, geriatric trials received emergency funding and regulatory fast-tracks in the infectious field.
Sponsor analysis underscores capacity disparities – for instance, industry giants such as Pfizer pared back non-COVID pipelines to prioritize vaccine R&D, while universities in lower-income regions pressed ahead with ongoing studies. This happened sometimes because there was simply no alternative funding source to pivot toward.
Finally, masking practices remind us that methodology bends to crisis pressures. Double-blind designs, which are gold-standard but cost a lot, gave way to pragmatic open-label approaches when courier networks, investigational pharmacies, and on-site monitoring collapsed.
Visualizations of the Data
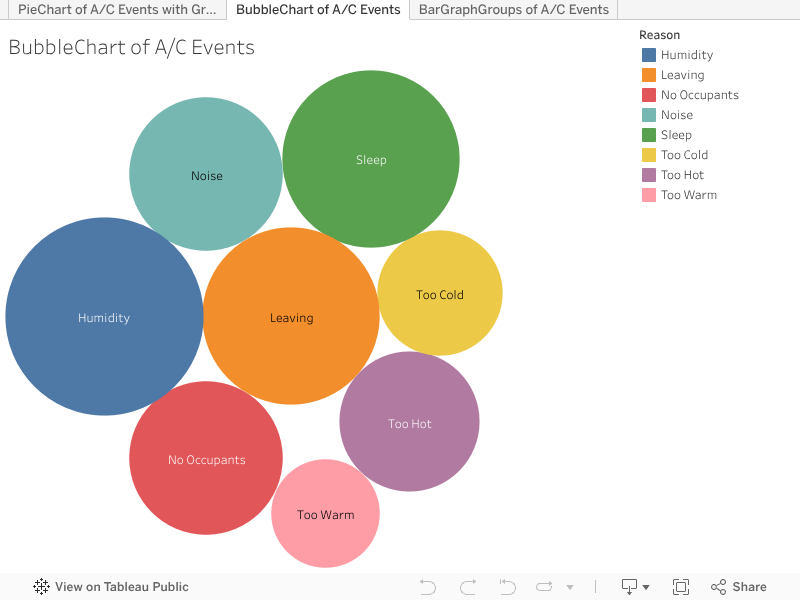
- Clinical Trial Treemap of Attempts, Successes, and Failures
The treemap categorizes all studies from the AACT database into three outcomes: attempted, succeeded, and failed, and allows users to switch between three different time periods. In the baseline from 2015 to 2019, the “Attempts per Year” category clearly dominated, showing that new interventional trials were registered. Within this large group, “Successes per Year” represented a significant share while the “Failures per Year” category was much smaller. About 30% of trials remained unfinished at the time of the 2025 snapshot.
Moving the filter to the pandemic period of 2020–2021 shrinks the total number of trials significantly. Attempts dropped but the decline in successful completions was even greater. Although failures also decreased, this change was less noticeable because total attempts fell so sharply. The increased empty space represents trials that did not complete or fail but were delayed significantly.
Switching to the recovery period from 2022–2025 shows a partial rebound. Total attempts rose again but only to a fraction of their original level, which shows renewed interest in starting new trials. However, successful completions did not recover as strongly and still now have, reaching less than half of their pre-pandemic level. Then, the small number of failures in post-recovery highlights that most newer trials have not yet reached completion, leaving even more unfinished studies.
As we step back and look at these shifts, they reveal a clear story: COVID-19 significantly disrupted the start and completion of clinical trials. Although new registrations have returned close to normal, a substantial backlog of incomplete trials remains. This backlog suggests ongoing delays in evidence generation, unless regulatory agencies and funders can help speed up late-stage trial activities.
2. Clinical Trial Line Graph of Age Groups
The line graph shows how often clinical trials specifically included children under eighteen and adults aged sixty-five and older. When the pandemic started, the percentage of trials including children dropped, and even though this decrease might seem small, it represents a significant reduction across thousands of studies. I believe this happened because schools closed, parents became reluctant to visit hospitals, and pediatric units redirected resources to COVID-19 care.
During the same period, trials welcoming older adults rose. This increase largely came from new vaccine, antiviral, and therapeutic studies aimed at seniors, the group most vulnerable to severe COVID-19 illness. Regulatory guidelines from 2020 and 2021 also encouraged researchers to include seniors, which led ethics committees to quickly approve broader age ranges.
In the recovery period from 2022 to 2025, the patterns shifted slightly back toward pre-pandemic levels, but not entirely. Pediatric inclusion rose again, nearly returning to its earlier level as pediatric research groups resumed work and remote consent methods improved. However, senior inclusion dropped slightly once the urgent need for COVID-specific trials decreased and researchers again narrowed eligibility criteria to reduce risks and simplify monitoring.
If we look at these visualizations together, these trends highlight how quickly demographic priorities in clinical research can change during a crisis. They also show that such changes can have lasting effects. Pediatric trials are still below their pre-pandemic participation rate, meaning fewer studies and less evidence for children’s health. Unless research funders and ethics boards actively support balanced inclusion, this gap might continue even after the pandemic ends.
3. Clinical Trial Top 20 Sponsors
The bar chart ranks the twenty most active trial sponsors and lets users switch between three different periods defined by the pandemic. This helps show how the types of institutions involved changed over time. Between 2015 and 2019, academic medical centers led the way, far ahead of industry leaders like AstraZeneca. Most of the other top spots were also held by universities and national hospitals, which shows that investigator-led research was the main driver of trial activity before COVID-19.
Switching the filter to 2020-2021 changes the picture in two noticeable ways. First, Cairo University’s share increased, likely because it continued smaller, single-site studies while wealthier institutions paused their non-essential research. Second, Pfizer’s ranking rose sharply due to its rapid launch of multiple vaccine, booster, and antiviral trials. Even though Pfizer’s total number of trials was relatively small, each trial counted separately, greatly increasing its presence. Other big companies like AstraZeneca and Novartis also saw modest increases, but none matched Pfizer’s rapid rise.
Moving the filter to 2022-2025 shows another shift. Several U.S. academic institutions slightly fall in rank, not due to fewer studies, but because universities in China and the Middle East continue rapidly expanding their trials in oncology and metabolic diseases, outpacing growth in the West. Pharma companies have shaken off the pandemic and have returned closer to their pre-pandemic levels as they shift back to focused, priority-based trial strategies once the vaccine rush ended.
Overall, these changes illustrate decentralized resilience. During COVID-19, global clinical research did not rely solely on a few large pharmaceutical companies; instead, thousands of smaller, low- and middle-income academic institutions like Cairo University kept the process moving. While pharmaceutical companies made targeted, significant contributions (especially Pfizer) the recovery in trial numbers since 2021 has been driven mostly by universities, particularly from Asia and the Middle East. Policymakers should recognize that supporting public research institutions may offer more consistent stability than depending solely on commercial sponsors whose involvement varies greatly with changing priorities.
Conclusions and Future Research
The pandemic exposed several weaknesses in the clinical-research system, yet it also highlighted the community’s ability to adapt quickly under pressure. Different sectors showed varying levels of resilience. Academic medical centers and smaller sponsors mostly kept their research moving forward, while the heavily regulated pharmaceutical industry paused, adjusted, and eventually restarted with fewer, high-priority projects.
One clear consequence of this disruption was the neglect of pediatric trials. Children’s clinical research relies heavily on school-based recruitment, parental consent, and specialized hospital resources, which were all severely impacted during lockdowns and resource shortages. Protecting pediatric trials should become a primary focus for ethics committees and funding organizations in future emergency planning.
The pandemic showed the importance of flexible methods in research. When in-person visits became impossible and placebo supplies faced disruptions, researchers switched to open-label or single-blind methods. Regulatory agencies can maintain the quality of research during future crises if they approve backup plans in advance. This will allow trials to adapt quickly without losing important data or accuracy.
Several important areas need further study. Researchers should examine geographic differences closely to see if stricter lockdown measures caused more delays or dropouts in clinical trials. Analytical methods that measure completion time, instead of just success or failure, would provide a clearer picture of the pandemic’s impact. I also think that looking at this data by month will show us more of an immediate view of the impact the shutdown and the pandemic starting in February and March of 2020. There also needs to be a way to make a visualization of this data by looking at the Phases of each trial that was attempted, either successfully or not.
Identifying exactly where the clinical research system broke down will allow stakeholders to strengthen these weak points. Making these improvements now ensures that essential medical research can continue smoothly during future global disruptions, keeping the process moving forward to save lives.